이렇게 기존에도 규제 기관의 허가까지 받은 ‘자율 의료 인공지능’이 있었음에도 불구하고, 왜 지금 이 개념을 살펴보는 것이 중요할까요? 바로 기존의 자율 인공지능과 최근에 나온 자율 인공지능에 근본적인 차이가 있기 때문입니다.
자율 의료 인공지능의 근본적 차이 (1) 사용 목적의 범용성
가장 직접적인 차이점은 바로 사용 목적(intended use)이 한정(narrow)되어 있는가, 그리고 알고리즘이 고정(static)되어 있는가의 여부입니다. 또한 출력의 재현성에서도 차이가 납니다. 이러한 차이는 이런 자율 인공지능이 기반으로 하고 있는 기술적 기반이 과거의 지도학습에 기반하고 있는지, 아니면 생성형 인공지능 기술에 기반하고 있는지에 기인합니다. 그 결과, 자율 의료 인공지능의 ‘자율도 (level of autonomy)’에 근본적인 차이가 생겨납니다. 즉, 인공지능 기술이 발전하면서 ‘진정한 의미’의 자율성을 가진 의료 인공지능에 계속 더 가까워지고 있다는 것이지요.
먼저 사용 목적의 범위를 살펴보겠습니다. 기존의 자율 인공지능의 사용 목적은 단일 질환이나 단일 과업에 한정되어 있습니다. 루미네틱스코어는 당뇨성 망막병증 진단, 덤은 피부암 진단으로 사용 목적이 국한되어 있습니다. 의사의 개입 없이 자율적으로 판단을 내리기는 하지만, 그 범위가 한 가지 종류의 문제에 국한된다는 것입니다.
반면 새로운 자율 인공지능은 사용 목적의 범위가 하나의 문제에 국한되지 않고, 더 넓은 범위에서 범용적으로 활용될 수 있습니다. 닥트로닉을 보면, 마치 내과, 가정의학과 전문의에게 진료를 받는 것처럼, 1차 진료 전반에서 다양한 건강 문제에 대한 상담, 진단, 처방하기 위한 목적으로 활용됩니다. 굳이 이야기 하자면, 사용의 목적이 열려 있다(open-ended), 개방되어 있다, 혹은 적어도 특정 범위 내에서는 범용적(general-purpose)이라고까지 표현할 수 있습니다. 이후에 더 설명하겠습니다만, 이 차이는 FDA나 식약처와 같은 의료기기 규제 기관에게 엄청난 고민거리를 안겨주게 됩니다.
자율 의료 인공지능의 근본적 차이 (2) 동적 알고리즘
두번째는 알고리즘이 얼마나 고정되어 있는지의 여부입니다. 기존의 자율 인공지능을 포함한, 기존의 의료 인공지능은 알고리즘이 개발이 완료된 이후에는 거의 변하지 않습니다. 즉, 알고리즘이 고정(static)되어 있습니다. 특히 의료 인공지능은 많은 경우 FDA나 식약처에서 의료기기로 인허가를 받고서 시장에 출시되는데, 이런 규제 기관들은 기본적으로 고정된 알고리즘, 즉 배포 시점에 동결되어서 사용 중에는 변하지 않는 소위 ‘잠겨 있는 알고리즘(locked algorithm)’을 전제로 합니다. 이 알고리즘도 변경을 할 수는 있지만, 이때는 제조사가 명시적으로 모델을 재학습시키고, 규제 기관의 재심사를 거친 후에, 새로운 버전으로 배포하는 통제된 사이클을 따릅니다. (최근 FDA는 PCCP (Predetermined Change Control Plan) 제도를 통해 사전에 정의된 변경 범위를 미리 승인하는 길은 열어두었지만, 이 역시 제조사 통제 하의 명시적 업데이트에 한정됩니다.)
예를 들어, 루미네틱스코어는 FDA 승인을 받은 시점의 알고리즘이 6개월 뒤에도, 1년 뒤에도, 그리고 다른 병원의 다른 환자에게도 완전히 동일하게 작동합니다. 같은 안저 사진을 1년의 간격을 두고 넣어도 완전히 같은 결과가 나오며, 어제 진료한 환자가 오늘 진료한 환자에게 어떠한 영향도 주지 않습니다. 새로운 임상 연구 결과가 발표되어도 모델에는 (명시적인 버전 변경이 아니라면) 반영되지 않습니다.
반면, 생성형 인공지능 기반의 새로운 자율 의료 인공지능은 (상대적으로) 더 동적(dynamic)이고, 적응형(adaptive) 알고리즘에 기반합니다. 비록 (ChatGPT나 닥트로닉도) 기반 모델 자체는 동결시킨 채 운영하지만, 생성형 인공지능 기반의 시스템은 프롬프트, RAG(검색 증강 생성, Retrieval-Augmented Generation), 도구 호출 로직, 가드레일 등 여러 층이 각각 독립적으로 시스템의 행동을 결정합니다. 이 각각의 층이 독립적으로 변경 혹은 업데이트될 수 있습니다. 프롬프트만 변경되어도 시스템의 행동이 달라지며, RAG 지식베이스에 임상 가이드라인이 변경되거나, 최신 연구 결과가 추가되거나, 가드레일의 기준이 바뀌면 시스템의 판단이 달라집니다. 특히 RAG나 가드레일은 주 단위, 때로 일단위로 업데이트될 수도 있습니다. 이런 점들을 고려하면 생성형 인공지능 기반의 모델은 일종의 동적인 유기체에 가깝습니다.
더 나아가면, 모델이 맥락에 따라서 행동을 조정하기도 합니다. 예를 들어, 환자와 대화를 나누면서 맥락을 학습하여(in-context learning), 그 맥락에 따라서 행동을 환자에 맞게 변경할 수 있다는 것입니다. 이는 기본 모델 자체를 변경하지는 않지만, 해당 환자를 진료하는 세션 내에서는 다른 맥락으로 행동하고 판단을 내릴 수 있게 됩니다. 예를 들어, 닥트로닉이 환자 A와 대화하면서 이 환자의 병력과 최근 약물 복용 및 부작용 등에 대한 맥락을 추가로 알게 되면, 해당 세션에 국한해서는 모든 후속 판단이 이 맥락을 반영하여 조정됩니다. 이는 어떤 의미에서는 사람 의사처럼 행동하는 것에 가깝다고 할 수 있습니다.
자율 의료 인공지능의 근본적 차이 (3) 출력의 재현성
세번째는 출력의 재현성 문제입니다. 즉, 동일한 입력을 넣으면, 동일한 출력이 나오는가에 대한 것입니다. 기존의 자율 인공지능은 기본적으로 결정론적(deterministic) 시스템입니다. 즉, 같은 안저 사진을 루미네틱스코어에 100번 넣으면, 100번 모두 동일한 결과가 나옵니다.
하지만 생성형 인공지능 기반의 자율 인공지능은 확률론적(stochastic) 시스템입니다. (ChatGPT, 클로드와 같은 생성형 인공지능이 그러하듯이) 닥트로닉에도 같은 환자, 같은 증상, 같은 병력을 여러번 입력하면, 조금씩 다른 판단이 나올 수 있습니다. 이는 시스템의 결함이라기보다 생성형 인공지능 자체의 본질적 작동 원리에서 기인합니다. 기술적으로 보자면, LLM은 다음 단어를 확률 분포에서 샘플링해서 생성합니다. 같은 입력을 주어도 매번 확률에 따라 조금씩 다른 답변이 나오도록 설계되어 있습니다. 이를 줄이려고 온도(temperature)를 0으로 설정하는 경우에도, 닥트로닉과 같이 여러 단계의 추론과 도구 호출을 거치는 멀티 에이전틱 구조에서는 결국 출력의 변동이 누적되어 나타나므로, 입력이 같아도 출력이 다를 수 있습니다.
이는 결과적으로 사람 의사의 자율성에 더 가까운 모습이라고 할 수도 있습니다. 같은 환자가 와도 (의사도 사람인 이상) 의사도 매번 조금씩 다른 판단을 내릴 수 있기 때문입니다. 계속 설명하겠지만, 이러한 특성 역시, 자율형 의료 인공지능을 기존 시스템 하에서 어떻게 허가하고 규제할 것인지에 대해서 매우 어려운 문제들을 만들어냅니다.
AI 에이전트, 자율 의료 인공지능의 기본 토대
아마도 여기까지 읽으신 분들은 ‘에이전트(agent)‘라는 용어가 자연스럽게 떠오르실지도 모르겠습니다. 현재 인공지능 분야의 가장 중요한 키워드 중의 하나는 단연 AI 에이전트입니다. 그리고 이 에이전트가 가진 자율성이라는 속성 자체가, 자율 의료 인공지능이 가지는 근본적인 특징이자, 기술적인 근간이 됩니다. 이 때문에 향후 자율 의료 인공지능은 이러한 AI 에이전트, 더 나아가서는 멀티 에이전틱 AI에 기반할 가능성이 높습니다. 그래서 이 에이전트를 간략히 살펴보고 넘어가겠습니다.
에이전트에 대한 단 하나의 정의가 있는 것은 아닙니다만, OpenAI의 응용인공지능 부서 책임자였던, 릴리안 웡(Lilian Weng)의 2023년 글에서는 Agent = LLM + Memory + Planning + Tool Use 으로 정의합니다. 즉, LLM이 두뇌 역할을 하고, 여기에 기억, 계획, 도구 사용 능력이 결합된 시스템이라는 것입니다. OpenAI는 2025년 글에서 “사용자를 대신해 독립적으로 작업을 완수하는 시스템”으로 정의하고 있습니다. 앤트로픽은 2024년 글에서, 에이전트를 “LLM이 스스로 자신의 프로세스와 도구 사용을 동적으로 결정하는 시스템”으로, 2025년 후속 글에서는 “LLM이 자율적으로 도구를 루프 안에서 사용하는 것”으로 정의하였습니다. 여기서 ‘루프’란 LLM이 한번의 응답으로 끝내지 않고, 사용자의 개입 없이 추론 → 도구 사용 → 결과 관찰 → 다시 추론의 사이클을 자동으로 반복하는 실행 구조를 의미합니다.
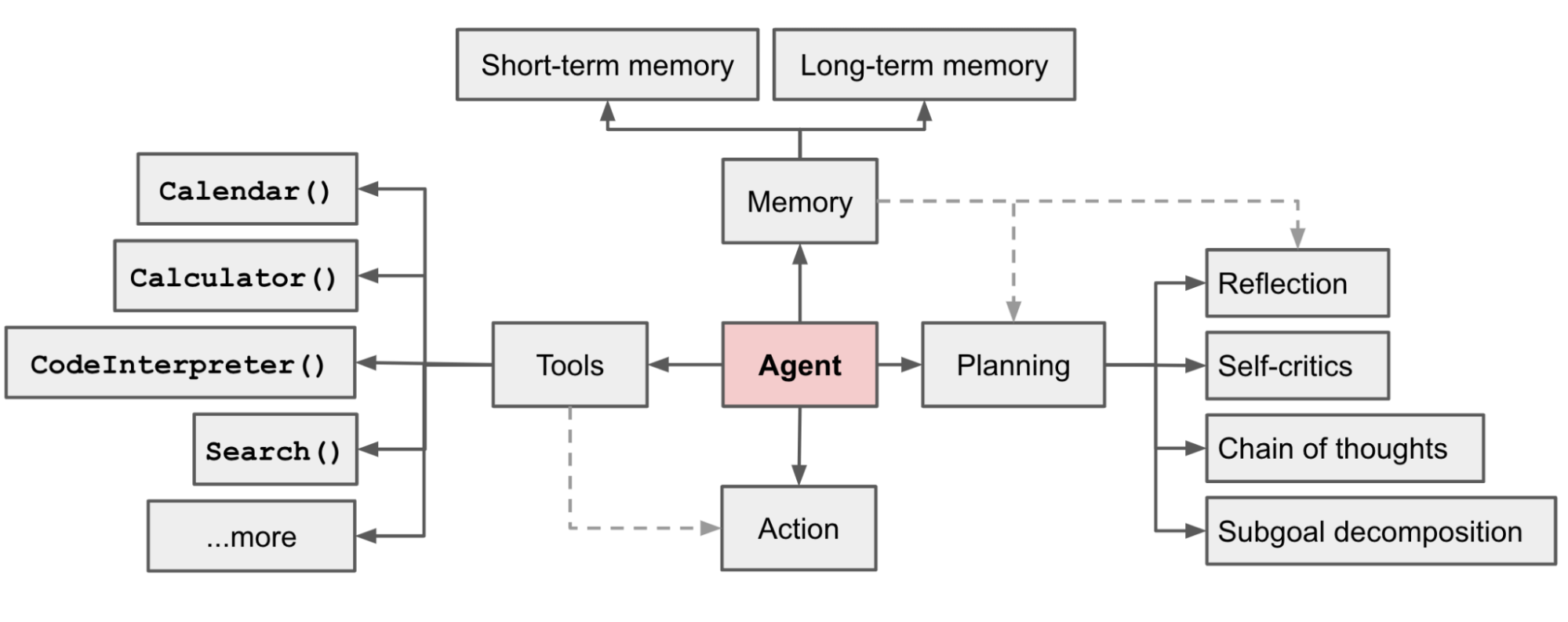
정리하자면 AI 에이전트는 자율성, 능동성, 목표지향성과 의사결정능력을 가질 뿐만 아니라, 이를 실행에 옮길 수 있는 도구까지 갖추어, 사용자를 대신해 독립적으로 과업을 완료하는 시스템을 의미합니다. 즉, 에이전트는 그 자체로 자율성을 가지기 때문에, 사람이 개입하지 않는 자율 인공지능으로 발전하기 위한 기본적인 토대가 된다고 할 수 있겠습니다.
특히, 2025년 셀 리포트 메디슨(Cell Report Medicine)에 실린 논문에 따르면, 의료 분야의 AI 에이전트의 구성 요소를 아래와 같이 정의하기도 합니다.
- 계획(Planning): LLM이나 LVM을 기반으로 한 에이전트의 인지 코어. 복잡한 입력을 분석하고 추론하여 의사 결정을 내리는 사고 방식을 담당. EHR, 검사 결과, 의학 문헌, 임상 가이드라인 같은 이질적 데이터를 통합해 근거 기반 추론을 수행.
- 행동(Action): 계획을 실제 세계의 변화로 옮기는 실행 인터페이스. 진단 보고서를 작성하고, 처방 권고, 수술 로봇 제어, 실시간 환자 모니터링, 의료진 알림 등의 작업을 수행.
- 성찰(Reflection): 에이전트가 환경으로부터 감각적 데이터를 받아들이고 해석하는 지각 능력. 의료 영상을 분석해 이상 소견을 탐지하고, 활력 징후를 실시간으로 분석.
- 기억(Memory): 시간에 걸쳐 정보를 축적하고 인출하는 기능으로, 단기 기억과 장기 기억으로 구분. 이 기억 덕분에 에이전트는 새로운 데이터가 누적될수록 판단을 정교화하며, 정적 알고리즘에 머무르는 전통적 의료 AI와 차별화 된다.
더 나아가면, 이러한 에이전트가 각각 개별적으로 작동하지 않고, 여러 에이전트가 모여서 서로 토론하고, 비판하고, 협업하는 것을 소위 멀티 에이전틱 AI (multi-agentic AI)라고 합니다. 각 에이전트가 특화된 역할을 수행하고, 서로 자연어로 정보를 교환하거나 업무를 분담하는 것입니다. 하나의 에이전트가 과업을 수행할 때보다, 이렇게 여러 에이전트가 함께 목표를 지향하게 되면, 더욱 어렵고도, 복잡한 과업을 달성할 수 있을 것이라고 기대되고 있습니다.
특히 의료에서 환자를 진료, 진단, 치료한다는 것 자체가 여러 전문 분야의 다양한 역할을 가진 사람(여러 진료과의 전문의, 간호사, PA, 코디네이터 등등)이 협업하는 것이기 때문에 , 의료가 그 자체로 ‘멀티 에이전틱’ 과업이라고 할 수 있습니다. 이 때문에 병원에서 환자를 진료, 진단, 치료하는 것을 여러 전문의가 협진을 하듯이 여러 에이전트의 협업을 통해서 진행하거나, 더 나아가서 병원 자체를 에이전트 기반으로 만들겠다는 개념도 나오고 있습니다. [1, 2, 3]
뿐만 아니라, 일상적인 건강 관리, 감별 진단, 간호 업무, 더 나가서는 신약개발과 같은 기초 의학 연구를 인간의 개입 없이 자율적으로 수행하기 위해서도 멀티 에이전틱 AI의 활용이 시도되고 있습니다. 사실 닥트로닉 인공지능도 병력 청취, 임상 추론, 진료 노트 (SOAP 노트)를 작성하는 등의 100개 이상의 에이전트로 구성되어, 각 에이전트가 특정 임상 업무를 담당하는 구조의 멀티 에이전틱 AI입니다. 앞으로도 새롭게 등장할 자율 의료 인공지능은 이렇게 멀티 에이전틱 AI에 기반할 가능성이 높습니다.
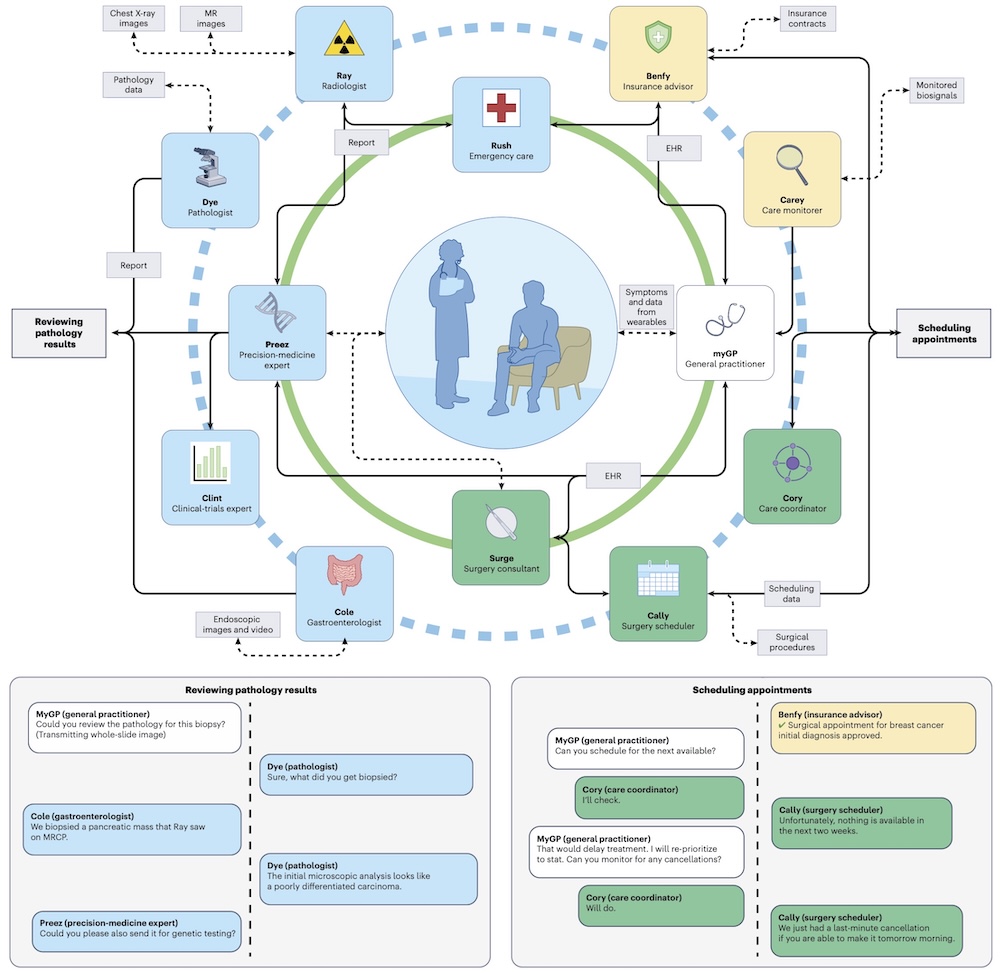
MIRA: EHR 안에서 행동하는 자율 의료 인공지능
이러한 새로운 자율 의료 인공지능의 대표적인 사례로, 2026년 6월에 네이처에 발표된 MIRA(Medical Intelligence for Reasoning and Action)를 들 수 있습니다. 독일 드레스덴 공대와 하이델베르크대 병원 연구진이 발표한 연구로, MIRA는 전자의무기록(EHR)과 통합되어 환자와 대화를 나누며 병력을 청취하고, 필요한 검사와 영상 검사, 미생물 검사를 오더하고, 그 결과를 해석하며, 감별 진단을 내리고, 약물 처방, 시술 계획, 그리고 입원에 대한 결정까지 수행하는 AI 에이전트입니다. 즉, 진료의 흐름을 따라가며 임상적인 의도를 가지고 이를 EHR과 연계된 구체적인 행동을 자율적으로 수행하는 인공지능이라고 할 수 있습니다.
조금 더 구체적으로는, 이 에이전트는 11가지 종류의 도구를 호출해서, (모든 도구에서 선택 가능한 옵션을 모두 합하면) 85,000개가 넘는 임상적인 행동 공간(action space)에서 의료 행위를 수행합니다. 예를 들어, PatientHistory(환자 과거력 조회), PhysicalExaminationRequest(신체검진), LabRequest(혈액검사 등 검사실 검사), UrineRequest(소변검사), RadiologyRequest(영상검사), ProcedureRequest(시술 예약), Admission(입원 결정) 등의 도구를 활용할 수 있는 것입니다. (앞서 설명한 ‘에이전트’의 정의에 ‘도구’ 사용을 동적으로 결정할 수 있다는 내용이 언급된 것을 상기해보자)
연구진은 MIRA를 샌드박스 형태의 EHR 환경에서 8개의 응급질환 (충수염, 담낭염, 게실염, 폐색전증, 췌장암, 췌장염, 폐렴, 요로감염 등)에 걸친 574 개의 사례에 대해서 두 종류의 의사 그룹 (7-11년 경력의 전문의 4명, 혼합 경력(레지던트 4명+영상의학 전문의 1명 + 혈액종양 전문의 1명))과 비교해보았습니다. 그 결과 MIRA는 87.8%의 진단 정확도를 보이면서, 전문의 그룹(78.1%)와 혼합 그룹 (71.1%)를 상회했습니다. 더 나아가, 가이드라인에 대한 준수, 약물 안전성 (신기능에 따른 용량 조정, 약물 상호작용 등), 입원 판단 등에서도 의사 그룹과 동등하거나 , 더 나은 결과를 보였습니다.
즉, MIRA는 의료 시스템 안에서 스스로 정보를 수집하고, 판단하고, 행동하는 자율 의료 인공지능의 전형을 보여주고 있습니다. 물론 아직은 이 연구가 실제 현장에서 실제 환자에게 적용된 것이 아니라, 샌드박스 안의 통제된 환경 하에서의 성과입니다. 하지만 자율 의료 인공지능의 가능성과 미래에 의료 시스템에서 자율 의료 인공지능이 어떠한 방식으로 구현될지에 대한 구체적인 그림을 보여준다는 점에서 의미가 큽니다.

MIRA가 자율 인공지능의 조건에 부합하는 이유
MIRA를 앞서 설명한 ‘기존’ 자율 의료 인공지능과 ‘새로운’ 자율 의료 인공지능이 어떻게 근본적으로 다른지를 기준으로 조금 더 살펴보겠습니다.
먼저, 사용 목적의 범용성입니다. MIRA의 사용 목적은 단일 질환이나 단일 과업에 국한되지 않습니다. 먼저 진료 대상이 충수염, 담낭염, 췌장염 같은 외과적 복부 질환부터 폐렴, 요로감염, 폐색전증 같은 내과적 응급, 그리고 췌장암 같은 종양학 영역까지 해당됩니다. 더 중요한 것은, 병력 청취에서 검사, 진단, 치료, 입원에 이르는 응급실 진료의 전 과정을 처음부터 끝까지(end-to-end) 수행한다는 점입니다. 루미네틱스코어가 당뇨성 망막병증 진단이라는 하나의 질환과 하나의 과업에 제한되어 있던 것과 대조적입니다.
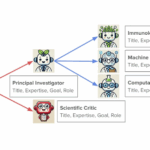
둘째로 에이전트가 동적인 의사 결정을 내립니다. MIRA는 여러 툴을 호출하여, 다음 단계를 계획하고, 검사에 대한 오더를 내리며, 그 결과를 해석하고, 이를 기반으로 다음 행동을 다시 계획합니다. 이러한 추론과 행동의 순환은 입원 결정에 이를 때까지 자율적으로 반복됩니다. 이는 앞서 에이전트의 정의에서 언급한 “추론 → 도구 사용 → 결과 관찰 → 다시 추론의 사이클을 자동으로 반복하는 실행 구조”의 전형을 보여주는 것으로, 아래의 그림은 MIRA가 수행하는 여러 임상적 추론 및 행동의 순환 구조를 시각화해서 잘 보여주고 있습니다.
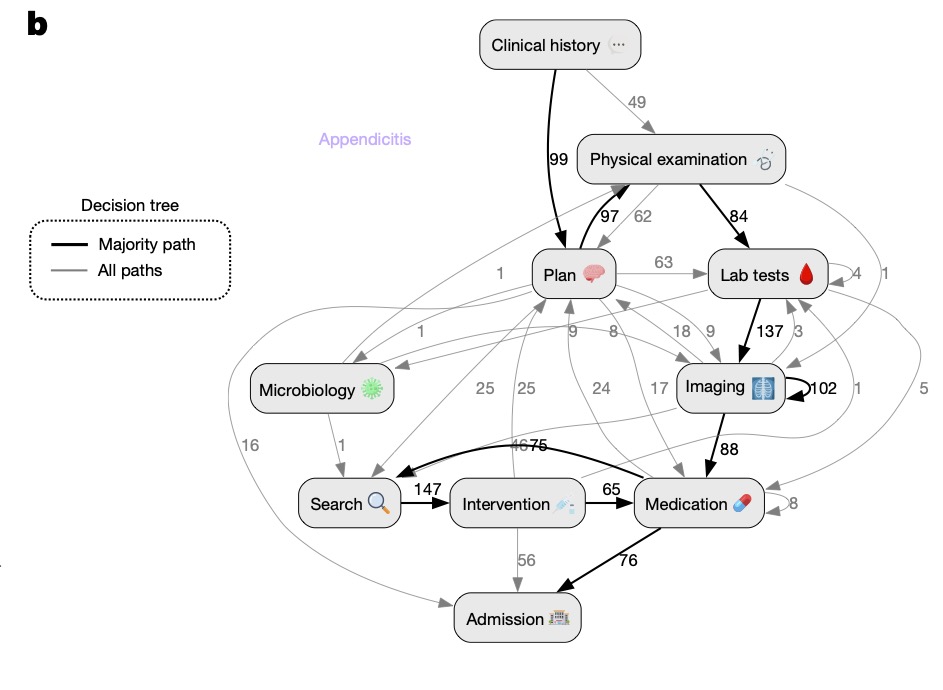
세번째로 결과의 비재현성입니다. MIRA의 경우 출력의 재현성 문제가 복잡해집니다. 환자에게 어떤 질문을 할지 결정하고, 어떤 혈액 검사와 영상 검사를 주문할지 선택하며, 그 결과를 해석하고, 감별진단을 내리는 등 여러 단계의 추론과 도구 호출을 반복적으로 해야 하기 때문입니다. 즉, MIRA의 출력값은 환자 진료 경로 전체라고 할 수 있는데, 같은 환자 정보를 여러번 입력하더라도 매번 동일한 진료 경로가 나올 것이라고 기대하기는 어렵습니다. 최종 진단은 같더라도, 그 진단에 도달하기까지의 질문, 검사, 처방, 입원 판단의 순서와 조합이 달라질 수 있다는 것이지요.
결국 이는 사람 의사가 진단하는 모습과 닮아 있습니다. 사람 의사의 경우에도, 같은 환자를 보더라도 의사마다 문진의 순서, 검사 선택, 감별 진단의 우선 순위, 치료 계획이 조금씩 달라질 수 있기 때문입니다.
자, 그렇기 때문에 우리는 다시 중요하고도 핵심적인 질문을 던질 수밖에 없습니다. 우리는 이렇게 인간 의사의 개입 없이 자율적이고 독립적으로 임상적인 의사 결정을 내리고, 의료 행위를 수행할 수 있는 ‘존재’를 어떻게 정의하고 규정해야 할까요?
(3편으로 이어집니다)
글쓴이
최윤섭
디지털 기술과 생명과학, 의학의 융합을 통해 사회적 가치를 창출하고 의료를 혁신하는 것을 화두로 삼고 있는 디지털 헬스케어 전문가, 미래의료학자, 작가, 벤처투자자입니다. 포항공과대학교(POSTECH)에서 컴퓨터공학과 생명과학을 복수전공하였으며, 전산생물학으로 이학박사 학위를 취득하였습니다. Stanford University 방문연구원, 서울대학교병원 연구조교수를 역임하였습니다. 현재 디지털 헬스케어 스타트업 전문 투자사 디지털 헬스케어 파트너스(DHP)의 대표 파트너이며, 연세대학교 의과대학 예방의학교실 외래조교수이기도 합니다. 『디지털 헬스케어: 의료의 미래』, 『의료 인공지능』, 『헬스케어 이노베이션』 등을 집필하였으며, Science의 제1저자를 비롯해서, 주요 국제 학술 저널에 다수의 논문을 개제하였습니다. npj Digital Medicine Editorial Board 멤버이자, 대한의료인공지능학회 설립 발기인 및 기획이사로 활동했습니다. 식약처 및 심평원의 자문위원이기도 합니다.
최윤섭의 디지털 헬스케어에서 더 알아보기
구독을 신청하면 최신 게시물을 이메일로 받아볼 수 있습니다.