최근 놀랍게도 초지능(superintelligence)을 운운하는 의료 인공지능이 등장했습니다. 더구나 그 인공지능을 개발한 곳이 마이크로소프트 AI 팀이어서 더욱 놀라웠는데요. 이 연구에 대해서 살펴보려 합니다.
결론부터 이야기하자면 초지능은 좀 오버스러운 이야기이고, 요즘 주목 받는 멀티-에이전트 모델을 활용해서, 실제 의료 환경에 가까운 조건에서 초인간적인 진단 퍼포먼스를 얻었다. 정도로 정리할 수 있는 연구였습니다. (‘초지능’은 이 연구를 소개한 MS의 웹페이지 포스팅에 제목으로 나옵니다만, 해당 연구 논문의 본문에는 초지능과 관련한 언급은 없고 ‘superhuman performance’라는 표현은 나옵니다.)
비록 ‘초지능’은 아니었지만, ‘초인간적’이라고 표현해도 무리가 없을만큼 인간 의사 대비 높은 성능을 보여주었으며, 다양한 측면에서 여러 시사점과 생각해볼 거리를 주는 흥미로운 연구입니다.
순차적 진단 (Sequential Diagnosis)
의료 인공지능에 대한 기술이 발전할수록, 이 모델의 성능을 어떻게 ‘잘’ 검증할 것인지가 중요합니다. 어떤 환경에서, 어떤 조건으로, 어떤 대상과, 무엇을 기준으로 비교해서 검증할 것인지 말이지요. 이제 단순한 환경에서 단순한 조건으로는 의료 인공지능의 성능이 너무도 좋게 나옵니다. 그렇기 때문에, 최근에는 어떻게 하면 ‘더 현실에 가까운’, ‘실제 의사가 환자를 진료하는 것과 유사한’ 환경에서 의료 인공지능을 테스트할지가 중요해지고 있습니다.
이 연구에서는 실제로 의사가 환자를 진료하는 것처럼 ‘순차적 진단 (sequential diagnosis)’를 인공지능이 잘 할 수 있는지를 테스트하였습니다. 이 연구에서는 한 번에 환자에 대한 모든 정보 (인적 정보, 주호소, 병력, 검사 결과 등)를 한꺼번에 주지 않았습니다. 대신, 처음에는 환자에 대한 아주 제한적인 정보만 제공한 다음에, 이를 바탕으로 모델이 질문, 검사 결과 등을 세부적으로 요구할 때마다, 그에 대한 환자의 정보 및 검사 결과를 순차적으로 제공하면서 인공지능이 진단을 진행하였습니다.
이 부분이 최근까지의 여러 유사한 연구와 가장 큰 차이점인데요[1, 2, 3]. 다른 연구들은 환자에 대한 정보를 한꺼번에 인공지능에게 제공한 다음에, ‘이를 바탕으로 감별 진단을 해보라’는 식으로 성능 테스트를 하였습니다. (논문에서는 이를 ‘static vignette’ 스타일이라고 명시합니다.)
하지만 현실에서는 의사가 환자를 이렇게 진단하지 않지요. 아주 제한적인 정보를 가지고 환자에게 여러 질문을 던지고, 추가적인 검사가 필요한지 판단하고, 그 검사를 시행해서 결과를 확인하고, 이를 종합해서 진단을 내릴 수 있을 것인지 자체를 결정하고, 그리고 최종적인 진단을 내립니다.
이 연구에서는 인공지능을 이렇게 테스트 합니다. 이를 위해 ‘순차적 진단 벤치마크(SDBench)’를 만들었는데요. 요즘에 ‘어려운 의학적 문제’를 위해서 많이 사용되는 NEJM의 임상병리 컨퍼런스(CPC) 케이스에 기반하여, 인공지능 모델이 특정 질문을 던지거나 검사 결과를 요청하면, ‘게이트키퍼’ 모델이 SDBench에 기반하여 그 질문 혹은 검사 결과에 대한 답을 해줍니다. (만약 케이스에 명시되어 있지 않은 정보를 물어보면, ‘게이트키퍼’가 적절하게 현실적인 ‘합성 정보(synthetic findings)’를 만들어서 제공하게 됩니다.)
그러면 그 답을 받은 모델이, 이를 기반으로 다시 새로운 질문 혹은 검사 결과를 게이트키퍼에게 요청하면서, 이렇게 반복적인 라운드를 거치면서 최종적인 진단을 내리는 것이 이 연구의 디자인입니다.

참고로, NEJM의 CPC 케이스는 의사들도 어려워하는 복잡하거나, 희귀한 환자의 사례들을 (병리학적으로 확진까지 끝난 케이스를) 바탕으로, 의학 교육용 목적의 증례 발표입니다. NEJM이 세계 최고의 의학저널이자, 의사들도 어려워하는 케이스이기 때문에 최근 여러 의료 인공지능 연구에서는 이 케이스들을 활용하고 있습니다. 이 연구에서는 2017년부터 2025년까지 발행된 304개의 NEJM CPC 사례를 활용하고 있습니다. (이 중에 56개를 테스트셋으로 사용)
MAI-DxO: ‘멀티-에이전트 인공지능’ 모델의 구성
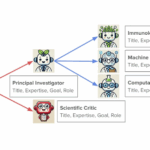
이 연구에서 중요하고도 흥미로운 것은 이 모델이 요즘 유행하는 ‘멀티 에이전트 모델’로 구성되어 있다는 것입니다. 즉, 하나의 인공지능 모델이 문제를 해결하는 것이 아니라, ‘여러개’의 각자 다른 구체적인 역할을 맡은 인공지능이 서로 토론을 하면서 한 라운드의 결론을 내린다는 것입니다. 마치 실제 의료 현장에서 어려운 질병에 대해서는 여러 진료과의 의사들이 토론하고 의견을 모으는 것과도 비슷하다고 할 수 있습니다.
연구자들은 이 연구에서 개발한 모델을 MAI-DxO (Microsoft AI Diagnostic Orchestrator) 라고 명명하였습니다. 여러 인공지능 모델을 마치 ‘오케스트라’처럼 활용하는 모델이라는 것이지요. 그렇다면, 이 ‘멀티 에이전트 모델’인 MAI-DxO를 어떤 모델들로 구성할지가 중요할텐데요. 이 연구에서는 아래와 같은 총 5가지의 모델로 구성하였습니다.
• Dr. Hypothesis: 가장 가능성 높은 3가지의 감별 진단을 유지하면서, 새로운 발견이 있으면 각 감별진단의 확률을 업데이트
• Dr. Test-Chooser: 주요 가설들을 최대한 구별하는 라운드당 최대 세 가지 진단 검사를 선택
• Dr. Challenger: 감별 진단 후보들에 대한 앵커링(anchoring) 편향을 식별하고, 모순되는 증거를 강조하며, 현재 주요 진단을 반증할 수 있는 검사를 제안하는 ‘Devil’s Advocate’ 역할
• Dr. Stewardship: 동일한 경우 더 저렴한 대안을 선호하고, 가성비 낮은 검사를 거부함으로써 비용 효율적인 진료를 추구
• Dr. Checklist: 추론 과정 전반에서 일관성과 퀄리티를 유지하도록 유도
이렇게 5가지의 모델들이 각 라운드에서 주어진 정보를 바탕으로 ‘토론’을 통해서, 결과적으로 ‘질문을 던지거나’, ‘검사를 요구하거나’, ‘진단을 내리는’ 세 가지 중의 하나를 하게 됩니다. 이를 다시 SDBench를 바탕으로, 게이트키퍼 모델이 답을 주면, 그 다음 라운드가 시작되는 식입니다.
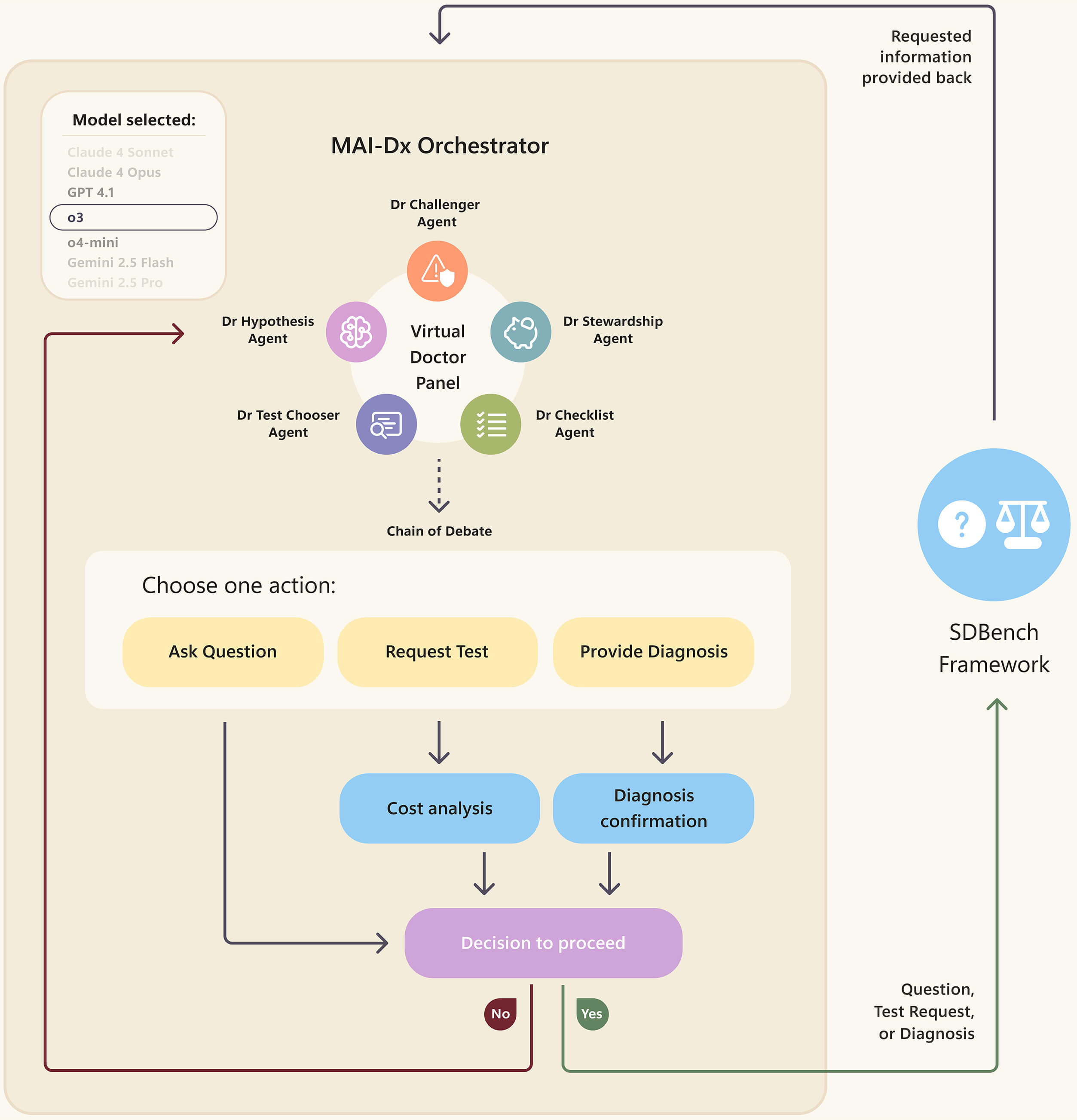
여기서 5개의 모델들은 모두 LLM입니다. 즉, 각 모델에 언어가 입력되면, 그 결과를 언어로 출력하여 (사람들이 하는 것처럼) 서로 언어를 주고 받으면서 토론을 하게되는 것입니다. 그러면 이 연구에서는 어떤 LLM을 사용하였을까요?
이 연구의 또 다른 가장 큰 특징 중의 하나는 바로, 이 MAI-DxO을 구성하는 각 에이전트 모델이 특정 LLM에 국한되지 않는다는 것입니다. 즉, 어떤 언어모델이든 활용할 수 있기 때문에 (이를 논문에서는 model-agonistic 하다고 표현합니다), MAI-DxO는 확장성이 매우 높다고 할 수 있습니다. MAI-DxO는 GPT-4.1을 위주로 개발되었지만, 이 연구에서는 Open AI, 앤트로픽, 구글, 메타, xAI, 딥시크 등의 다양한 LLM을 MAI-DxO의 각 에이전트로 퍼포먼스 테스트를 한 결과를 보여주기도 합니다.
초인적인 성능
그러면 그 결과 MAI-DxO는 어떤 성능을 보여줬을까요? 이 연구에서의 모델의 ‘성능’을 평가하기 위한 지표로는 진단 정확도와 케이스별 평균 ‘비용’의 두 가지를 활용하였습니다.
흥미로운 것은 진단 정확성 뿐만 아니라, 다른 의료 인공지능 연구에 잘 나오지 않는 ‘비용’을 주요 지표로 설정하였다는 것입니다. ‘비용’은 의료와 인공지능 모두에서 매우 중요한 지표입니다. 왜냐하면 두 마리의 토끼를 모두 잡기가 어렵기 때문입니다.
의료에서는 소위 ‘철의 삼각’이라는 잘 알려진 개념이 있는데요. ‘의료의 질, 비용, 접근성 3가지 모두를 극대화하는 것은 불가능하다’는 컨셉입니다. 그만큼 의료를 평가하기 위해서 비용은 세 가지 주요 축의 하나를 구성할만큼 중요하다는 의미이며, 일반적으로 의료의 질을 높이려면, 비용이 높아질 수밖에 없게 됩니다.
그리고 인공지능에서, 특히 LLM과 같은 초거대 인공지능에서 비용은 너무도 중요한 문제이지요. 초거대 인공지능은 말 그대로 모델이 크기 때문에 문제를 풀 때마다 많은 계산이 필요하고, 이는 결국 데이터 센터, 전기 등의 비용으로 직결됩니다. 일반적으로 모델의 크기가 커지면 성능도 더 좋아지는 대신, 결국 비용이 더 많이 들어가게 됩니다. 특히, 최근 여러 빅테크 기업들이 앞다투어 경쟁적으로 모델의 크기를 더욱 키워가는 상황에서 비용은 더욱 중요합니다.
여튼, 결과적으로 Open AI의 o3를 MAI-DxO를 구성하는 에이전트로 활용했을 때의 퍼포먼스가 가장 좋았습니다. o3를 사용했을 때에도 다양한 조건으로 테스트를 하였는데, (1) 예산에 제한을 둔 경우, (2) 예산에 제한을 두지 않았을 경우, (3) 예산에 제한을 두지 않으면서 + 앙상블 모델을 활용한 경우 등이었습니다.
이 중에 (3) 예산에 제한을 두지 않으면서, 앙상블 모델을 활용한 경우의 진단 정확도가 (당연히) 가장 높았는데 85.5%에 달했지만, 비용도 $7,850으로 높았습니다. (2) 예산에 제한을 두지 않는 경우도 진단 정확도는 81.9% 에, 비용은 $4,735. (3) 예산에 제한을 두는 경우 평균 테스트 비용 $2,396에, 진단 정확도는 79.9%를 기록했습니다. 즉, 세 경우 모두 진단 정확도는 80%, 혹은 이상입니다.
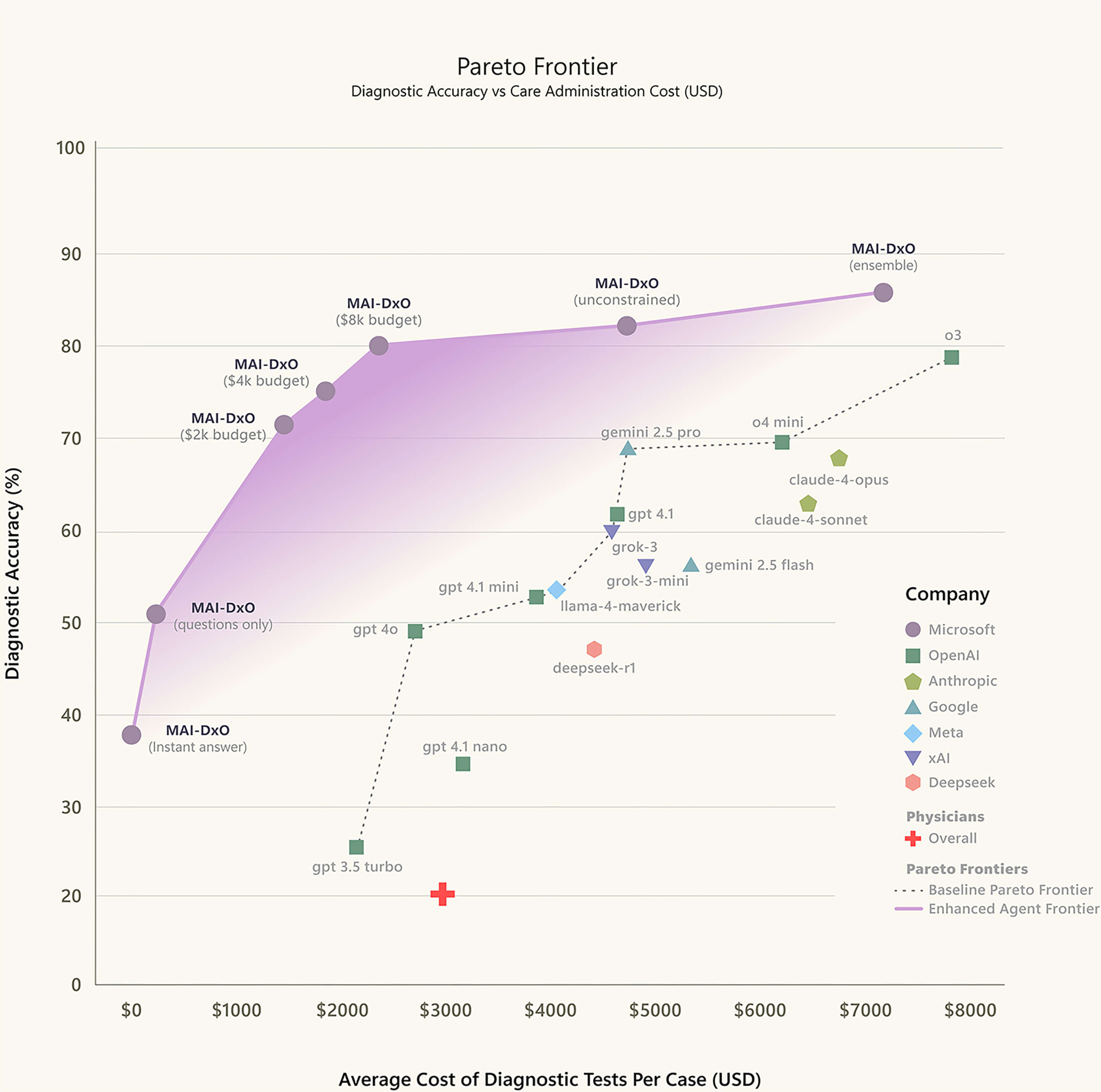
이는 여러모로 시사하는 바가 큽니다. 무엇보다 인간 의사의 평균적인 정확도가 20% 밖에 되지 않습니다. 즉, o3 기반의 MAI-DxO의 정확도가 인간 의사보다 4배나 높습니다. 마이크로소프트의 웹페이지에서는 ‘초지능’이라고 언급되며, 논문에서는 ‘초인적 (superhuman)’이라고 언급되는 것이 이 때문입니다.
이 연구에 대조군으로 참여한 인간 의사들은 총 21명이며, 경력의 중간 값은 12년이었습니다. 다만, 21명 모두 전문의가 아니었습니다. 17명은 1차 진료 의사(primary care physicians)였고, 4명은 병원 내 일반의(in-hospital generalists)였습니다. 즉, 전문의가 아니었기 때문에 조금 약한 대조군이라고 볼 수도 있습니다. (대조군에 대해서는 흥미로운 논의가 있는데, 후술하겠습니다.)
특히 인간 의사들의 경우, 이 연구에서는 케이스당 $3,000 정도의 비용이 든다고 추산하고 있습니다. 앞서 언급했듯이, o3 기반으로 예산에 제한을 둔 MAI-DxO의 경우, 정확도는 79.9%인데 비용은 $2,396입니다. 즉, 인간 의사보다 4배 정확하면서도 비용은 더 저렴합니다.
또 하나의 비교 대상은 (논문에서 off-the-shelf 라고 표현되는) LLM을 그냥 쓰는 것입니다. 즉, o3 기반의 MAI-DxO가 아니라, 그냥 o3만 쓰는 것이지요. 어떤 LLM 모델인지에 따라서, off-the-shelf 의 퍼포먼스는 상당히 차이가 납니다. 그리고 모든 LLM의 경우에 off-the-shelf 보다는, MAI-DxO으로 구성하는 것이 진단 정확도가 더 높아집니다. (얼마나 높아지는지는 차이가 있습니다.)
흥미로운 것은 o3는 MAI-DxO로 해도 정확도가 높지만, off-the-shelf로 해도 정확도가 높습니다. Off-the-shelf의 경우에도 진단 정확도가 78.6%나 나오고, MAI-DxO로 구성해서 80% 이상이 나옵니다. MAI-DxO로 해도 진단 정확도가 크게 높아지지 않는다고 볼 수도 있습니다만, 대신 off-the-shelf 대비 비용이 줄어듭니다. O3의 off-the-shelf의 경우 비용이 $8,000 정도나 들기 때문입니다.
연구의 의의
이 연구는 여러 의의를 지니며, 또한 몇가지 생각해볼 점들을 던져 줍니다.
앞서 언급했듯이 이 연구는 실제 의료 현장에서 의사가 환자를 진단하는 방식과 유사한 ‘순차적 진단’을 인공지능이 잘 할 수 있다는 것을 증명한 연구입니다. 기존에 유사한 연구들은 대부분 이러한 ‘순차적 진단’이 아니라, 필요한 모든 정보를 한꺼번에 주는 ‘정적 vignette’ 스타일이었다는 중요한 차이가 있습니다 특히, 그러한 결과 ‘초인적 역량’이라고 해도 무리가 없을만큼, MAI-DxO 모델이 인간 의사 대비 4배나 높은 진단 정확도를 보이면서도, 비용은 더 저렴하다는 놀라운 결과를 보여주고 있습니다.
더 나아가, 이 연구는 최근 주목을 받고 있는 ‘멀티-에이전트 인공지능’ 모델을 활용했다는 것도 의미가 있습니다. 하나의 인공지능이 아니라, 가설 생성, 진단 검사 선택, 반론 제기, 가성비 추구 등의 여러 역할을 하는 여러 인공지능 모델이 서로 ‘토론’을 거쳐서 (중간) 결론을 내리는 것을 반복하였습니다. 저는 아직 이런 ‘멀티-에이전트 인공지능’ 모델을 신약 개발 등에 활용한 초기 연구들은 보았지만, 환자의 진단에 활용을 시도하는 아직은 몇 안되는 연구 결과로 보입니다.
더구나, MAI-DxO는 특정 LLM에 국한되지 않는다(model-agnostic)는 장점이 있습니다. 즉, o3보다 더 성능이 좋은 LLM을 활용하게 되면, 이번 연구 결과보다 진단 정확도는 더 높아질 것입니다.
또한 이 연구는 진단 정확도 뿐만 아니라, ‘비용’도 중요한 지표로 삼고 있습니다. 제가 일선 강의 등에서 많이 받는 질문 중의 하나가, 인공지능 등의 의료 기술이 발전되면, 결국 의료 서비스의 빈익빈 부익부가 심해지는 것 아닌가 하는 것입니다. 돈이 많은 환자는 이런 기술 혁신의 수혜를 받지만, 가난한 환자는 그림의 떡 아니냐는 것인데요.
이 연구에서는 MAI-DxO를 구성하는 여러 에이전트 중에 Dr. Stewardship이라는 가성비 낮은 검사를 거부하고, 비용 효율적인 진료를 추구하는 에이전트를 포함시키고, 예산을 (다양한 규모로) 제한하여 인공지능의 진단 정확도를 테스트하였습니다. 그 결과, 무한대의 예산을 활용한 경우보다는 당연히 진단 정확도가 떨어지지만, 예산을 상당히 제한한 경우에도 의사들보다 저렴한 비용으로, 4배 높은 진단 정확도를 달성할 수 있다는 것을 보여주었습니다. (제가 앞으로 비슷한 질문을 받으면, 이 연구 결과를 예시로 들어서 답변드리면 될 것 같습니다.)
더 생각해볼 점
그리고 이 연구는 몇가지 중요한 생각거리를 던져 줍니다. 그 중에 제게 가장 흥미를 끌었던 것은, 인간 의사와의 진단 정확도를 어떻게 비교해야 할지에 대한 부분입니다.
인간 의사들은 보통 넓은 분야에 대한 상대적으로 얕은 지식을 갖춘 제너럴리스트와 좁은 분야에 깊은 전문성을 가진 전문의로 구분할 수 있습니다. 의학이 한 명의 개인이 넓고 & 깊은 전문성을 가지기에는 너무도 방대하기 때문입니다. 그렇기 때문에, 의료 전달 체계 등의 ‘시스템’을 갖춰서 다양한 역할의 의사가 각기 다른 역할을 가지고 협업하여 현대 의료를 구성합니다.
그런데 이제는 선도적인 AI 모델들이 이러한 전통적인 구조에 도전하고 있다고 논문에서는 언급합니다. 폭과 깊이를 모두 갖춘 인공지능들이, 여러 전문 분야에 걸쳐서 의학적인 추론 능력을 발휘하고 있다는 것이지요. 즉, 이런 모델들은 제너럴리스트의 범위와 전문의의 깊이를 모두 가지고 있어서, 이 연구에서 보여준 것처럼 NEJM CPC 케이스와 같은 복잡한 진단 의사에서 개별 의사보다 훨씬 뛰어난 능력을 보여줍니다. 그리고 그 격차는 앞으로 더 벌어질 것이라고 생각합니다. (물론 이 연구에서는 전문의가 아닌, 일반의들의 진단 결과와 비교하였습니다만, 개별 케이스에 맞는 진료과의 전문의들의 결과와 비교했더라면 결국 ‘폭’이 문제가 되었을 것입니다)
특히, 이번 연구와 같은 여러 개의 인공지능으로 구성된 ‘멀티-에이전트 인공지능’ 모델의 성능과 인간 의사의 실력을 비교하기 위해서는, (이번 연구처럼) 개별 의사의 진단 결과와 비교하는 것이 아니라, 어쩌면 여러 명의 제너럴리스트 및 전문의들로 구성된 다학제간 의료진 ‘그룹’과 비교를 하는 것이 더 적절하다고 볼 수 있지 않을까요.
어떤 인공지능의 어떤 측면을 검증하고자 하느냐에 따라서 달라지겠지만, 의학의 폭과 깊이를 모두 갖춘, 특히 ‘멀티-에이전트 인공지능’을 어떻게 검증할 것인지는, 미래에 의료 인공지능의 역할을 어떻게 정의할 것인지와 맞물린 중요한 질문이라고 생각합니다.
글쓴이
최윤섭
디지털 기술과 생명과학, 의학의 융합을 통해 사회적 가치를 창출하고 의료를 혁신하는 것을 화두로 삼고 있는 디지털 헬스케어 전문가, 미래의료학자, 작가, 벤처투자자입니다. 포항공과대학교(POSTECH)에서 컴퓨터공학과 생명과학을 복수전공하였으며, 전산생물학으로 이학박사 학위를 취득하였습니다. Stanford University 방문연구원, 서울대학교병원 연구조교수를 역임하였습니다. 현재 디지털 헬스케어 스타트업 전문 투자사 디지털 헬스케어 파트너스(DHP)의 대표 파트너이며, 연세대학교 의과대학 예방의학교실 외래조교수이기도 합니다. 『디지털 헬스케어: 의료의 미래』, 『의료 인공지능』, 『헬스케어 이노베이션』 등을 집필하였으며, Science의 제1저자를 비롯해서, 주요 국제 학술 저널에 다수의 논문을 개제하였습니다. npj Digital Medicine Editorial Board 멤버이자, 대한의료인공지능학회 설립 발기인 및 기획이사로 활동했습니다. 식약처 및 심평원의 자문위원이기도 합니다.
최윤섭의 디지털 헬스케어에서 더 알아보기
구독을 신청하면 최신 게시물을 이메일로 받아볼 수 있습니다.