

“디지털 의료는 어떻게 구현되는가” 시리즈 보기
- 변혁의 쓰나미 앞에서
- 누가 디지털 의료를 이끄는가
- 데이터, 데이터, 데이터!
- 4P 의료의 실현
- 스마트폰
- 이제 스마트폰이 당신을 진찰한다
- 웨어러블 디바이스
- 개인 유전 정보 분석의 모든 것!
- 환자 유래의 의료 데이터 (PGHD)
- 헬스케어 데이터의 통합
- 헬스케어 데이터 플랫폼: 애플 & 발리딕
- 빅 데이터 의료
- 원격 환자 모니터링
- 원격진료
- 인공지능
데이터, 데이터, 데이터!
“데이터! 데이터! 데이터!” 홈즈는 조바심을 내며 외쳤다.
“점토가 없는데 무슨 수로 벽돌을 만든단 말인가.”
– 아서 코난 도일, ‘셜록 홈즈의 모험-너도밤나무집의 비밀’ 중에서
디지털 의료에서 가장 중요한 한 가지 요소만을 꼽으라면 무엇을 골라야 할까? 이론의 여지는 있겠지만, 나는 다름아닌 ‘데이터’가 가장 중요하다고 생각한다. 디지털 의료에서 데이터는 새로운 재화이자, 새로운 권력이며, 새로운 경쟁 우위 요소가 될 것이다. 또한 데이터를 누가 소유하고, 접근권을 가지며, 어디에 저장하며, 어떻게 관리할 것인가가 매우 중요한 이슈로 부각될 것이다. 재무 분야의 오랜 격언 중에 ‘현금이 왕이다 (Cash is king)‘ 이라는 말이 있다. 여기에 빗대어 나는 디지털 의료에서는 ‘데이터가 왕이다 (Data is king)’ 라고 감히 이야기하고 싶다.
다소 거친 표현이지만, 우리 인간은 그 자체로 데이터다. 우리가 생명을 유지하고 살아가는 것 자체가 데이터를 생산해내는 과정이다. 우리가 숨쉬고, 먹고, 마시고, 심장이 뛰고, 혈액이 흐르고, 걷고, 뛰고, 땀을 흘리고, 잠을 자고, 느끼고, 말을 하는 모든 것이 데이터를 만들어낸다. 더 나아가 우리는 태어나면서 고유의 데이터를 가지고 있다. DNA 염기서열에 담겨 있는 유전 정보가 대표적이며, 유전 정보를 조절하고, 유전 정보에서부터 시작되는 많은 생명 현상이 모두 데이터다.
IBM이 분석한 바에 따르면, 우리 인간은 크게 세 가지 종류의 데이터를 만들어낸다. 의료 데이터, 유전체 데이터, 그리고 그 밖의 외부적인 데이터이다. 이러한 각 종류별로 인간이 평생 만들어내는 데이터의 크기를 보면 의료 데이터는 0.4 테라바이트, 유전체 데이터는 6 테라바이트에 그치는 반면 그 외의 외부적인 데이터(exogenous data)는 무려 1,100 테라바이트나 된다. 이 세 가지 종류의 데이터가 우리의 건강에 미치는 영향도 각각 10%, 30%, 그리고 60% 로 크게 차이가 난다.
 인간이 평생 만들어내는 데이터의 종류와 크기 (출처: IBM)
인간이 평생 만들어내는 데이터의 종류와 크기 (출처: IBM)
인간이 살아가면서 만들어내는 이 세 가지 데이터들 중에 우리가 현재 의료에 활용하고 있는 데이터는 무엇인가? 병원의 전자의무기록 (EMR)이나 종이 차트에 기록된 전통적인 의료 데이터 정도다. 유전체 데이터의 경우, 최근 유전 정보 분석 기술의 발전으로 이제야 서서히 의료 시스템 속으로 들어오고 있는 중이지만 암 치료 등 몇몇 예외적인 질병을 제외하고는 일상적인 의료에서의 활용은 여전히 제한적이다. 그리고 가장 큰 비중을 차지하는 그 밖의 외부적인 데이터는 현재의 의료 체계 하에서는 거의 사용하지 못하고 있다. 애시당초 이런 데이터를 측정한다는 것 자체가 불가능했기 때문이다. 적어도 최근까지는 말이다.
하지만 지금부터는 이야기가 좀 달라질 것이다. 인류 역사 최초로 우리는 인간을 디지털화할 수 있는 시대에 살고 있다. 즉, 예전에는 의미 없이 버려졌거나, 불완전하게 얻었던 데이터들이 이제는 기술적으로 측정 가능해지고 있다는 것이다.
웨어러블 센서, 사물인터넷, 스마트폰, 개인 유전정보 분석 등의 발전에 따라 측정 가능한 데이터의 종류, 양과 질 모두 과거와 비교할 수 없을 정도로 개선되고 있다. 더 나아가, 클라우드 컴퓨팅, 인공지능, 소셜미디어 등의 발전은 디지털 의료 데이터를 공유, 전송, 저장할 수 있게 해주며, 이러한 데이터를 통합하고 분석함으로써 질병을 예측하고, 예방하며, 치료하기 위한 새로운 인사이트를 얻게 해줄 것이다.
근거 중심 의료에서, 데이터 중심 의료로
이러한 의미에서 나는 ‘디지털 의료’를 지칭하는 또 다른 이름이 바로 ‘데이터 중심 의료 (data-driven medicine)’ 라고 생각한다. 최근 이 데이터 중심 의료는 현대 의학의 핵심적인 기조인 ‘근거 중심 의료 (evidence-based medicine)‘ 에서 한 단계 더 나아간 개념으로 쓰이기도 한다.
서로 비슷한 개념처럼 보일 수도 있겠지만, 여기에서 말하는 ‘근거’와 ‘데이터’의 차이는 크다. 무엇보다 이 두 개념의 범위에 차이가 있다. 근거 중심 의료에서 ‘근거’란 주로 병원 내부에서 측정되고 차트에 담겨 있는 협의의 의료 데이터를 의미했다면, 데이터 중심의료에서 ‘데이터’가 의미하는 바는 기존의 의료데이터뿐만 아니라, 개별 환자의 유전체 데이터와 외부적인 데이터를 포괄하고, 이를 통합, 분석, 예측하여 도출된 결과까지 확장된 개념이라고 할 수 있겠다.
 근거 중심 의료의 근거 수준 (level of evidence)
근거 중심 의료의 근거 수준 (level of evidence)
기존의 근거 중심 의료에서, 근거의 수준은 여러 단계로 나뉘어진다. (여러 기준들마다 약간의 차이가 있기는 하지만) 전문가의 경험적인 근거나, 한 명의 환자의 사례를 보고한 증례 보고 (케이스 리포트) 등이 가장 낮은 단계의 근거로 여겨진다.
이러한 개별적인 환자 사례들이 여럿 모이거나, 더 나아가서 질병을 가진 환자군과 그렇지 않은 대조군(control)을 비교하여 결과를 야기시킨 원인을 탐구하는 환자-대조군 연구(case-controlled study)나, 특정 위험요인에 노출된 집단과 그렇지 않은 집단을 비교하는 코호트 연구 (cohort study)로 갈수록 근거의 수준은 높아진다.
근거 중심 의학에서 가장 높은 수준의 근거는 다수의 환자에 대한 무작위 임상시험 (randomized controlled trial, RCT) 에서 얻어진다. 무작위 임상시험에서는 환자를 동전을 던져 앞뒤면이 나오는 것처럼 무작위로 실험군과 대조군에 배정하게 된다. 더 나아가서는 어느 환자가 실험군과 대조군에 배정되었는지를 연구자와 환자 모두 모르게 함으로써 (이를 이중 맹검(double-blinded)라고 한다), 편파적인 성향 (bias)을 최대한 배제한 신뢰도 높은 근거를 얻을 수 있다.
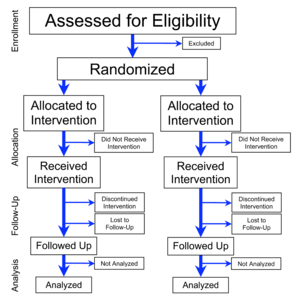
이렇게 근거 중심 의학에서는 대부분 임상 시험이나, 많은 사람을 모은 집단을 기반으로 결과를 도출하게 된다. 문제는 이런 실험군과 대조군에 속하는 다수의 사람들이 모두 개별적인 특징을 가지는 개별적인 사람이라는 것이다. 이 개인들은 각각 유전적, 환경적, 사회적으로 다양한 요인을 가지고 있는 존재들이다. 하지만 이런 개인들의 특성을 모두 반영할 수 없기 때문에, 기존의 패러다임 하에서는 해당 집단 내에서 평균적으로 잘 작동하는 모델을 찾아낼 수 밖에 없었다.
예를 들어, 어떤 신약에 대한 임상시험 결과 유의미한 효과가 있었다는 것을 결국 해당 집단의 사람들에게 평균적으로 대조군에 비해서 유의미한 효과가 있었다는 것이다. 수백명에서 많게는 수천 명, 수만 명으로 이루어진 이 임상 연구 집단은 전체 인구를 대표하는 일종의 표본 집단으로 간주될 뿐이다. 개개인이 아니라 말이다. 하지만 일정한 분포를 따르는 집단에서 평균적으로 약의 효과가 있다고 하더라도, 그 집단 내에서 어떤 사람은 평균 이상으로 약에 반응할 것이고, 어떤 사람에게는 평균보다 낮은 반응을 보일 것이다.
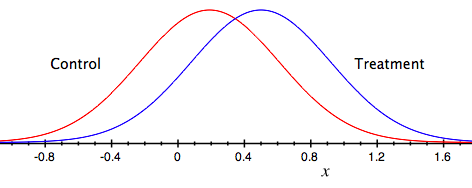
실험군과 대조군 분포의 통계적 차이에 따라 약의 효과 유무가 결정된다
대중을 기반으로 하는 근거 중심 의료에서 내가 만약 그 ‘평균’ 에 해당한다면 운이 좋은 것이다. 하지만 평균 이상이라면 나는 불필요하게 과도한 치료를 받는 것이 되고, 평균 이하라면 필요한 치료를 충분히 받지 못하는 것이 된다. 즉, 이 시스템 하에서는 평균에 해당하는 사람들을 제외한 나머지 모든 사람에게는 최적의 치료가 제공된다고 볼 수는 없는 것이다.
과거에는 이렇게 인구에 기반한 접근 방법이 최선이었다. 평균적인 근거에 기반한 의료를 통해서 현대 의학은 눈부신 발전을 이루었다. 다만 이제는 한 단계 더 발전할 수 있는 기술적인, 환경적인 준비가 갖추어졌다. 바로 데이터 중심 의료다.
근거 중심 의료가 인구 통계 기반의 근거를 기반으로 한다면, 데이터 중심 의료는 해당 특정 환자 개인에게서 나온 데이터를 중심으로 한다. 풍부한 각종 데이터를 기반으로 해당 환자의 상태를 명확하게 파악할 수 있고, 더 나아가서는 그 환자에게 맞는 최적의 치료법과 치료 시기를 파악할 수 있을 것이다. 근거 중심 의료에 비해, 데이터 중심 의료에서는 정량적이고, 폭 넓으며, 풍부한 데이터에 기반한다.
또한 과거에 특정 유전자의 유무, 특정 생체 지표 (biomarker)의 기준 수치 초과 여부 등의 정성적인 기준으로 환자의 집단을 세분화했다면, 이제는 다양한 항목의 정량적 수치에 기반한 복합적인 모델을 기반으로 개별 환자를 분류할 수 있다. 즉, 과거의 패러다임은 유사한 사람들을 몇가지 그룹으로 분류하는 방식이었다면, 새로운 모델에서는 개별 환자가 각각 독특한 특성을 가진 개인으로 간주할 수 있는 것이다.
데이터 중심 의료란: 스탠퍼드 병원의 사례
특히 기존의 근거 중심 의료 패러다임의 맹점 중의 하나는 기존에 참고할만한 임상 연구나 가이드라인, 문헌, 더 나아가 전문가들의 경험적인 근거까지 없는 경우라면 치료 의사 결정을 내리기가 어렵다는 점이다. 하지만 지금까지 축적되어온 방대한 데이터를 우리가 체계적으로 활용할 수 있다면, 예외적인 증상을 보이는 환자에 대해서도 의사결정을 내리는데 도움을 줄 수 있다.
세계 최고의 의학 저널인, 뉴 잉글랜드 저널 의학 저널 (NEJM)에 2011년 소개된 스탠퍼드 대학의 연구는 이런 데이터 중심 의료의 초기 형태를 보여준다. 13살 여아 환자가 전신홍반루푸스 (Systemic lupus erythematosus) 때문에 병원을 찾았다. 그런데 이 환자에게서 드물게도 신증후군 범위의 단백뇨(nephrotic range proteinuria), 항인지질항체 (antiphospholipid antibody), 췌장염 (pancreatitis) 증상까지 보이면서 문제가 복잡해졌다.
이런 증상들은 혈관 속의 혈액이 굳어져서 덩어리가 되는 혈전증(thrombosis)의 가능성을 보여주는 것이었지만, 이러한 조건의 환자에게 항혈액응고요법(anticoagulation)을 실시하는 것이 바람직한지에 대한 기존의 근거를 찾을 수 없다는 것이 고민이었다. 다수의 환자에 대한 임상 연구 결과가 없었을뿐만 아니라, 개별 환자에 대한 증례보고, 혹은 전문가들의 경험적인 근거조차도 부족했다.

이런 상황에서 스탠퍼드의 연구진은 전자의무기록(EMR) 내에 저장되어 있는 98명의 소아 전신홍반루푸스 환자의 중, 혈전증이 발생한 10명의 환자의 데이터를 분석했다. 이 환자들 중 신증후군 범위의 단백뇨와 췌장염이 있을수록 혈전증의 발병율이 통계적으로 높다는 것을 발견하고, 이 환자가 입원한지 24시간 내에 항혈액응고제를 투여할 수 있었다. 즉, 기존의 의료 데이터의 체계적인 분석을 기반으로 예외적인 환자에 대한 치료법을 결정할 수 있었던 것이다. 이 연구에서는 이 결론을 내리기 위해 의사 한 명이 4시간 정도를 컴퓨터 앞에 앉아서 데이터를 분석해야 했다.
이렇게 데이터에 기반하여 스탠퍼드 의료진들이 내린 의사결정은 향후 의료가 맞이할 모습에 대해서 많은 점들을 시사한다. 만약 이 사례가 아래와 같이 더 확장된다면 어떻게 될지를 상상해보자.
- 만약에 이 분석이 스탠퍼드 병원의 전자의무기록에 포함된 98명의 환자뿐만 아니라, 전세계 모든 병원의 전자의무기록에 포함된 비슷한 증상을 가진 수천 만 명의 환자를 비교 대상으로 한다면?
- 이 분석을 병원 내의 전자의무기록의 의료 기록뿐만이 아니라, 개인 유전 정보, 환자가 스스로 평소에 측정한 활력 징후, 생활 패턴, 활동량, 수면, 식사, 스트레스, 환경 정보까지도 통합해서 종합적으로 분석했다면?
- 이 분석이 사람이 직접 하는 것이 아니라, 인공지능으로 자동 분석하면서 데이터간 숨어 있던 상관관계와 통찰력까지 얻을 수 있다면?
- 질병이 발병하고 환자가 내원한 후에야 몇시간을 들여서 분석하는 것이 아니라, 항상 이 분석이 실시간으로 가동되고 있다면?
- 예외적인 증상을 보이는 일부 환자뿐만 아니라, 모든 환자에게 이런 분석이 진행된다면?
이러한 것이 아마도 데이터 중심 의료가 궁극적으로 지향하는 방향일 것이다.
*** 데이터 중심 의료의 개념 정립에 대해서는 경희사이버대학교 정지훈 교수님, VUNO의 의료정보학 전문가 감혜진 박사님께서 도움을 주셨습니다. 다시 한 번 감사드립니다.
(계속)
![[논문] LLM이 의료 전문가보다 의학 텍스트 요약을 더 잘 한다](https://www.yoonsupchoi.com/wp-content/uploads/2024/03/Untitled-8-140x90.png)
![[영상] 카카오 브레인의 배웅 최고 헬스케어 책임자(CHO) 님 인터뷰](https://www.yoonsupchoi.com/wp-content/uploads/2024/03/배웅-부사장님-140x90.jpg)

![[영상] 루닛 백승욱 의장님 인터뷰](https://www.yoonsupchoi.com/wp-content/uploads/2024/01/썸네일-종합.219-140x90.jpeg)
















3 Comments